The Art and Science of Vertical and Horizontal Scalability for DevOps
The Art and Science of Vertical and Horizontal Scalability for DevOps
Scalability is something that looks easy to understand but is something that not all IT Engineers are aware of, or dominating when they’re creating a new architecture. We should always consider scalability when we’re planning to create a new project and ask the right questions that will become reality soon.
Along with this article, I added some key questions that will make you think about and check your knowledge of scalability, vertical, horizontal, and auto-scaling. The answers will be provided at the end.

Question
- What is a key characteristic of vertical scalability in IT infrastructure?
a. Focus on distributing workloads across multiple servers
b. Emphasis on optimizing individual server components
c. Prioritizing cost-effectiveness over performance
d. Scaling by adding more servers horizontally
e. Implementing load-balancing techniques
Consider a web server that usually receives 500 requests per minute and responds with an access time of 15ms. Now the web server receives 1000 requests per minute and responds with an access time of 500ms. This is not the expected behaviour as we would hope that the increased response time would not be so dramatically impacted. For a system to be scalable, we expect its performance to be impacted proportional to the change in size or requests.

We refer to system scales by using one of these scales: constant scaling, linear scaling, and exponential scaling.
- Constant Scaling refers to a system performance that does not change as the system workload increases. In the above-mentioned example, we would expect the system to still respond at a rate of 15ms per request if it had constant scaling.
- Linear scaling means that system performance changes proportionately to the changes in system workload. For instance, since the workload doubled, we might expect a doubling of response time to 30ms.
- Exponential scaling refers to a system performance that changes disproportionately to the change in system workload. We might consider the above-mentioned example to be an example of exponential scaling. Of course, our preference is for a system to achieve constant scaling but this is not typically plausible, so we would prefer linear scaling.
- With linear scaling, we can offset the performance degradation caused by an increased workload by adding hardware. This is not the case if we are suffering from exponential scaling.
In the image below, we compare the three functions in modeling the response times of three websites, labeled Website 1, Website 2, and Website 3.

In this image, we see how the websites perform with different scaling factors as the number of users increases from 1 to 10. Specifically, the response time for Website 1 is described by function f(x)=50. Since the value is always 50, it is constant or the function represents constant scaling. For Website 2, the function that describes its response time is f(x)= 10x. This is an example of linear scaling because the function is the equation of the line (i.e., there are no exponents applied to the variable, x). For Website 3, the response time function is described as f(x)=2x⋅ex. This is an example of exponential scaling. From the curve, we can see that the response times for 1,2,3,4,5 and 6 concurrent users are 2,4,8,16,32 and 64ms, respectively. As we add users the response time doubles. This would be a disastrous situation if we expect more than about 10 users. If there were 20 concurrent users, the response time would be 2²⁰ ms, which is a little over a million ms. If there were 30 concurrent users, the response time would be 2³⁰ m, which is over a billion ms or a million seconds (over 11 days!).
2³⁰=2×2×2×…×2
This is equivalent to multiplying 2 by itself 30 times. The result is a very large number:
2³⁰= 1,073,741,824230
So, 2³⁰ is equal to 1,073,741,824. Which is in the billion range.
We can see that Website 1 accommodates any increased workloads very well. Website 2 has a reasonable performance although we would prefer less of a slope to the line so that, as there is an increase in users, the impact is not as great. Website 3 only works well for a very small number of concurrent users.
In the web environment, scalability is not about how fast a system is, but instead focuses on the question of how well the system performs, as we add more compute/network/storage resources to increase its capacity when increasing demands arise. Will the system’s performance improve proportionally to the increased capacity? If yes, it is a scalable system. There are several ways to scale a system.
Question
2. In deciding between horizontal and vertical scalability, what is a crucial factor to consider?
a. Total number of servers
b. Initial setup cost
c. Performance of individual components
d. Redundancy of network connections
e. Availability of cloud-based services
If this article has proven helpful for you until here don’t forget to share it with someone else!
Now let's say we need to scale our environment in the short future how about to discuss about Vertical Scaling and Horizontal Scaling?
Vertical Scaling
Vertical scaling is also called a scale-up approach. In this approach, larger and higher capacity hardware is used to replace the existing smaller capacity hardware for a system. In the below picture, we have an example of vertical scaling where the size of the server indicates its capacity. An organization might begin with a low-end server to host its website. As the business grows, the website traffic increases. Once the current server’s capacity is reached and cannot meet the increased demands, the business replaces it with a mid-end server that will eventually reach a point where its capacity has been exceeded. Again, the company replaced it this time with a high-end server. Vertical scaling is the easiest way to add capacity to a system but is very expensive because the organization is solving the problem by investing more money in higher-end servers while losing money on previously purchased servers. There is also an ultimate limit to what a top-of-the-line server will provide. Once purchased, the organization’s website would have no more room to grow. Any further increase in demand would cause a degradation in performance that vertical scaling could not solve.

Horizontal Scaling
Horizontal scaling is also called a scale-out approach. In this approach, additional hardware resources are added to a system and are placed side-by-side with the existing resources. In the below image, we have an example of horizontal scaling. A company might begin with a low-end server to host its website. That server is used until its capacity is reached. At that point, when performance begins to degrade, the company purchases another server of the same or similar type and capacity. Now, with two servers, they work side-by-side to fulfill the increased load. In this way, the workload is shared among both servers. If the company reaches a point where the two servers are no longer meeting the demands, a third similar, server is purchased and added to the system.

With horizontal scaling, resources can be added incrementally. This provides for greater flexibility than vertical scaling because can also be taken away if the demand is no longer needed and applied to other needs. We can also use horizontal scaling to improve reliability. With two servers, if one fails for a short while (or requires maintenance), we can continue to service requests through another available server. Performance might degrade for the time that the failed server is unavailable (or not replaced) but at least we will still be able to service requests.
Question
3. How does horizontal scalability primarily address increased demand in a distributed IT environment?
a. By enhancing the performance of individual components
b. By adding more resources to existing servers
c. By optimizing code efficiency
d. By upgrading server hardware vertically
e. By reducing the number of servers
More significantly, horizontal scaling is far more economically viable. The cost of moving from a low-end server to a mid-end server may be more than purchasing another low-end server (and similarly for the move from mid-end to high-end). Research has shown that the cost of vertical scaling increases exponentially and the cost of horizontal scaling increases linearly. In addition, as noted previously, through vertical scaling, we are discarding previously useful hardware. In horizontal scaling, all of the purchased hardware remains in use.
The drawback of horizontal scaling is that it is far more complex to set up and run effectively than vertical scaling. There are several reasons for this. First, we have to ensure that the servers in our horizontal cluster are compatible. Imagine that we want to purchase a second low-end server but the server we are currently using has been discontinued. Purchasing a different low-end server will have its problems such as having to use differently configured server software and having to rewrite server-side scripts. Of greater thought is the need to have some form of load balancing so that incoming requests will be sent to one of the available servers. Where will the load balancing balancing will we run? What load-balancing algorithm (s) we should use? Can we ensure we are making the best of our hardware through load balancing?
Comparing Horizontal vs Vertical Scaling
To better understand the differences between horizontal and vertical scaling, let’s take a closer look at each method and compare them side by side.
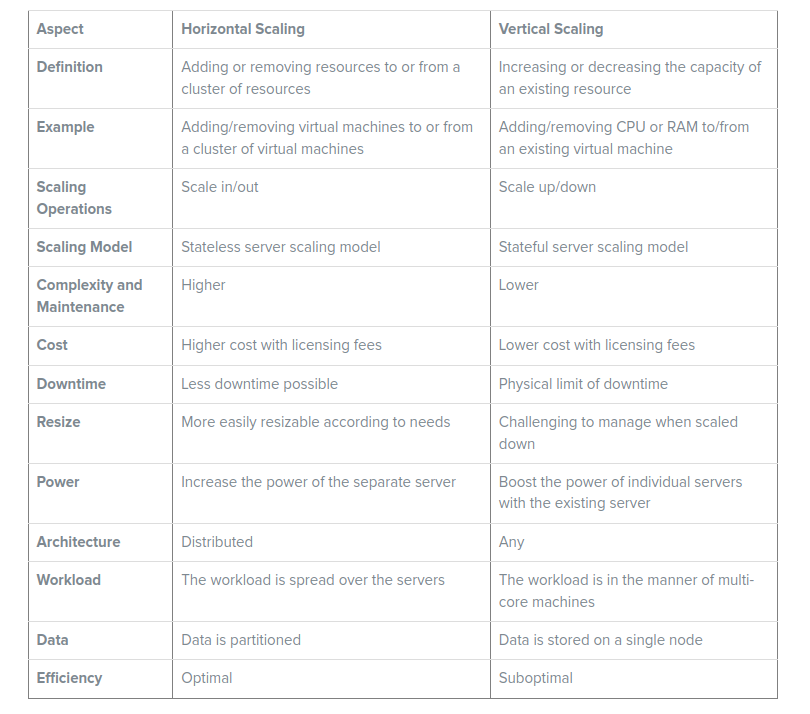
Autoscaling
We could not finish this article without seeing a bit about autoscaling, right? Let's go a little bit around some concepts from TechTarget about cloud auto-scaling.
Autoscaling provides users with an automated approach to increase or decrease the compute, memory, or networking resources they have allocated, as traffic spikes and use patterns demand. Without autoscaling, resources are locked into a particular configuration that provides a preset value for memory, CPU, and networking that does not expand as demand grows and does not contract when there is less demand.
Autoscaling is a critical aspect of modern cloud computing deployments. The core idea behind cloud computing is to enable users to only pay for what they need, which is achieved in part with elastic resources applications, and infrastructure that can be called on as needed to meet demand.
Autoscaling is related to the concept of burstable instances and services, which provide a baseline level of resources and then can scale up or “burst” as memory and CPU use come under demand pressure.

Autoscaling works in a variety of ways depending on the platform and resources a business uses. In general, several common attributes across all autoscaling approaches enable automatic resource scaling.
For compute, memory, and network resources, users will first deploy or define a virtual instance type that has a specified capacity with predefined performance attributes. That setup is often referred to as a launch configuration also known as a baseline deployment. The launch configuration is typically set up with options determined by what a user expects to need for a given workload, based on expected CPU use, memory use, and network load requirements for typical day-to-day operations.
With an autoscaling policy in place and enabled by an autoscaling technology or service, users can define desired capacity constraints so more resources can be added as traffic spikes stress resources. For example, with network bandwidth autoscaling, an organization can set a launch configuration with a baseline amount of bandwidth and then set a policy that will enable the service to automatically scale it up to a specified maximum amount to meet demand.
The purpose of autoscaling
Autoscaling enables cloud application workloads and services to deliver the optimum performance and accessibility service levels necessary under different conditions.
Without autoscaling, resources are strictly defined and constrained within a set configuration for a given set of resources. For example, if an organization has a large analytics workload that it needs to process, it might require more compute and memory resources than initially defined. With an autoscaling policy in place, computing and memory can automatically scale to process the data in a timely fashion.
Autoscaling is also necessary to help ensure service availability. For example, an organization could configure an initial set of instance types that it expects will be sufficient to handle traffic for a particular service. If a traffic spike occurs due to an event, such as Black Friday shopping, there can be a significant change from a typical use pattern for a service site. To maintain service availability in the event of a traffic spike, autoscaling can deliver the necessary resources for a service to continue executing operations efficiently while meeting customer demand.
Types of autoscaling
Fundamentally there are three types of autoscaling:
- Reactive. With a reactive autoscaling approach, resources scale up and down as traffic spikes occur. This approach is closely tied to real-time monitoring of resources. There is often also a cooldown period involved, which is a set period where resources stay elevated even as traffic drops to deal with any additional incremental traffic spikes.
- Predictive. In a predictive autoscaling approach, machine learning and artificial intelligence techniques are used to analyze traffic loads and predict when more or fewer resources will be needed.
- Scheduled. With a scheduled approach, a user can define a time horizon for when more resources will be added. For example, ahead of a major event or for a peak period during the day, rather than waiting for the resources to scale up as demand ramps up, they can be pre-provisioned in anticipation.
Autoscaling vendors
Some cloud vendors that provide autoscaling capabilities include:
- Amazon Web Services (AWS). AWS has multiple autoscaling services, including AWS Auto Scaling and Amazon EC2 Auto Scaling. AWS Auto Scaling is a service for users who need to scale resources across multiple AWS services. In contrast, the Amazon EC2 Auto Scaling service is focused on providing autoscaling capabilities for Amazon EC2 instances that provide virtual computing resources.
- Google Compute Engine (GCE). GCE provides autoscaling capabilities as a feature for its cloud users running managed instance groups of virtual machine (VM) instances. Managed instance groups are an optional deployment approach on Google Compute Engine, where groupings of identical virtual machines are deployed across GCE in a managed approach to enable higher availability.
- IBM Cloud. IBM has a module known as cluster-autoscaler that can be deployed on IBM Cloud workloads. This autoscaler can increase or decrease the number of nodes in a cluster based on the sizing needed as defined by scheduled workload policies.
- Microsoft Azure. For users of the Microsoft Azure cloud platform, the Azure AutoScale service enables automatically scaling resources. Azure AutoScale can be implemented with VM, mobile and website deployments.
- Oracle Cloud Infrastructure. Oracle has multiple autoscaling services across its Oracle Cloud Infrastructure platform, including Compute Autoscaling and a flexible load balancer that enables elastic load balancing for network traffic.
Summary
Deciding on a scaling strategy is a critical task that requires careful consideration of various factors such as performance, availability, cost, and traffic. Your choice should align with your business goals and ensure the smooth operation of your applications or websites. As a System Engineer, DevOps, or SRE, certainly you need to dominate the art of getting the requirements before starting a new architecture. I hope this article was helpful.
Answers
- Correct Answer: b
- Correct Answer: c
- Correct Answer: b
A TDEE calculator can be a valuable tool for those with specific dietary preferences or restrictions. For example, vegetarians, vegans, or individuals with food allergies can use the calculator to ensure they are getting enough calories and nutrients from their diet. By understanding their TDEE, they can plan meals that meet their caloric needs while adhering to their dietary preferences. This is particularly important for individuals who follow restrictive diets, as they need to be more mindful of their nutrient intake to avoid deficiencies.tdee calculator
ReplyDelete